
在MongoDB中使用MapReduce
概述※
MapReduce是个非常灵活和强大的数据聚合工具。它的好处是可以把一个聚合任务分解为多个小的任务,分配到多服务器上并行处理。MongoDB也提供了MapReduce,当然查询语肯定是JavaScript。
MongoDB中的MapReduce相当于关系数据库中的group by。使用MapReduce要实现两个函数Map和Reduce函数。Map函数调用emit(key,value),遍历Collection中所有的记录,将key与value传递给Reduce函数进行处理。
MapReduce的基本思想※
MapReduce 能够计算非常复杂的聚合逻辑,非常灵活,但是,MapReduce非常慢,不应该用于实时的数据分析中。MapReduce能够在多台Server上并行执行,每台Server只负责完成一部分wordload,最后将wordload发送到Master Server上合并,计算出最终的结果集,返回客户端。
MapReduce的基本思想,如下图所示:
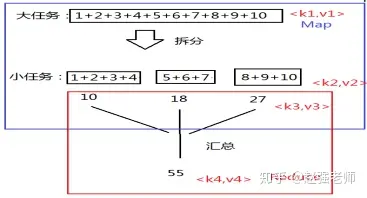
在这个例子中,我们以一个求和为例。首先执行Map阶段,把一个大任务拆分成若干个小任务,每个小任务运行在不同的节点上,从而支持分布式计算,这个阶段叫做Map(如蓝框所示);每个小任务输出的结果再进行二次计算,最后得到结果55,这个阶段叫做Reduce(如红框所示)。
使用MapReduce方式计算聚合,主要分为三步:Map,Shuffle(拼凑)和Reduce,Map和Reduce需要显式定义,shuffle由MongoDB来实现。
- Map:将操作映射到每个doc,产生Key和Value
- Shuffle:按照Key进行分组,并将key相同的Value组合成数组
- Reduce:把Value数组化简为单值
基本语法※
db.runCommand({
mapreduce:<collection>,
map:<mapfunction>,
reduce:<reducefunction>,
[,query:<query filter object>]
[,sort:<sorts the input objects using this key.Useful for optimization,like sorting by the emit key for fewer reduces>]
[,limit:<number of objects to return from collection>]
[,out:<see output options below>]
[,keeptemp:<true|false>]
[,finalize:<finalizefunction>]
[,scope:<object where fields go into javascript global scope>]
[,verbose:true]
});参数说明:
Mapreduce: 要操作的目标集合
Map: 映射函数(生成键值对序列,作为reduce函数参数)
Reduce: 统计函数
Query: 目标记录过滤
Sort: 目标记录排序
Limit: 限制目标记录数量
Out: 统计结果存放集合(不指定使用临时集合,在客户端断开后自动删除)
Keeptemp: 是否保留临时集合
Finalize: 最终处理函数(对reduce返回结果进行最终整理后存入结果集合)
Scope: 向map、reduce、finalize导入外部变量
Verbose: 显示详细的时间统计信息。举例说明※
我们以下面的测试数据(员工数据)为例,来为大家演示。
db.emp.insert(
[
{_id:7369,ename:'SMITH' ,job:'CLERK' ,mgr:7902,hiredate:'17-12-80',sal:800,comm:0,deptno:20},
{_id:7499,ename:'ALLEN' ,job:'SALESMAN' ,mgr:7698,hiredate:'20-02-81',sal:1600,comm:300 ,deptno:30},
{_id:7521,ename:'WARD' ,job:'SALESMAN' ,mgr:7698,hiredate:'22-02-81',sal:1250,comm:500 ,deptno:30},
{_id:7566,ename:'JONES' ,job:'MANAGER' ,mgr:7839,hiredate:'02-04-81',sal:2975,comm:0,deptno:20},
{_id:7654,ename:'MARTIN',job:'SALESMAN' ,mgr:7698,hiredate:'28-09-81',sal:1250,comm:1400,deptno:30},
{_id:7698,ename:'BLAKE' ,job:'MANAGER' ,mgr:7839,hiredate:'01-05-81',sal:2850,comm:0,deptno:30},
{_id:7782,ename:'CLARK' ,job:'MANAGER' ,mgr:7839,hiredate:'09-06-81',sal:2450,comm:0,deptno:10},
{_id:7788,ename:'SCOTT' ,job:'ANALYST' ,mgr:7566,hiredate:'19-04-87',sal:3000,comm:0,deptno:20},
{_id:7839,ename:'KING' ,job:'PRESIDENT',mgr:0,hiredate:'17-11-81',sal:5000,comm:0,deptno:10},
{_id:7844,ename:'TURNER',job:'SALESMAN' ,mgr:7698,hiredate:'08-09-81',sal:1500,comm:0,deptno:30},
{_id:7876,ename:'ADAMS' ,job:'CLERK' ,mgr:7788,hiredate:'23-05-87',sal:1100,comm:0,deptno:20},
{_id:7900,ename:'JAMES' ,job:'CLERK' ,mgr:7698,hiredate:'03-12-81',sal:950,comm:0,deptno:30},
{_id:7902,ename:'FORD' ,job:'ANALYST' ,mgr:7566,hiredate:'03-12-81',sal:3000,comm:0,deptno:20},
{_id:7934,ename:'MILLER',job:'CLERK' ,mgr:7782,hiredate:'23-01-82',sal:1300,comm:0,deptno:10}
]
);(案例一)求员工表中,每种职位的人数※
var map1=function(){emit(this.job,1)}
var reduce1=function(job,count){return Array.sum(count)}
db.emp.mapReduce(map1,reduce1,{out:"mrdemo1"})(案例二)求员工表中,每个部门的工资总和※
var map2=function(){emit(this.deptno,this.sal)}
var reduce2=function(deptno,sal){return Array.sum(sal)}
db.emp.mapReduce(map2,reduce2,{out:"mrdemo2"})另外一个图例※
举个MapReduce使用的例子,我们有一个orders表,包含cust_id,amount,status三个字段,现在我们有统计同一个cust_id的订单的总额。
可以像下面这样写:
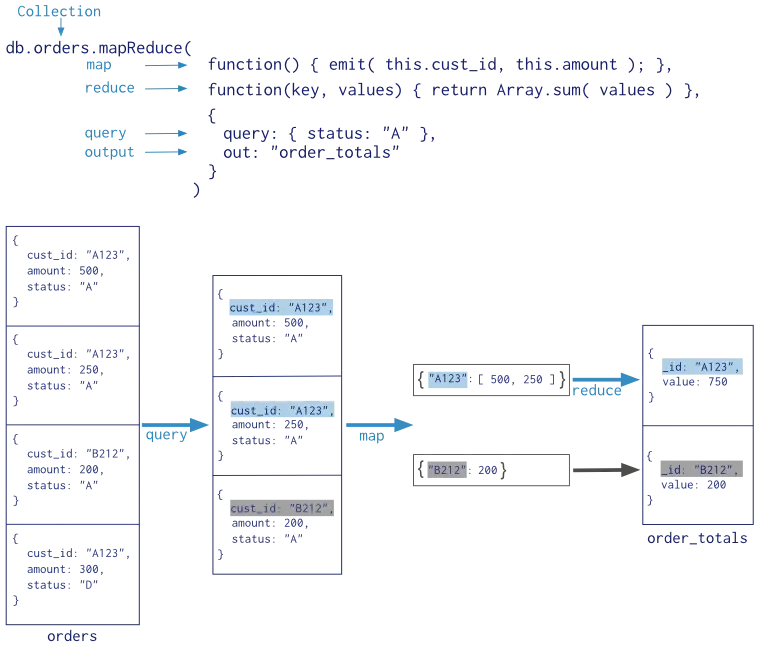
map-reduce
执行顺序显而易见:
1、执行query筛选出特定数据
2、执行map返回键值对,这里的值可以是一个list
3、执行reduce对value求sum
4、得到名为order_totals的结果


